
Probability has found itself a comfortable position amongst industry mathematics. And now, with the advancement of the computer age, a 100-year-old piece of maths has jumped to the forefront, namely Markov chains. These can be used for an awe-inspiring range of ideas including predicting the weather, mapping the probability distribution of a Monopoly properties, and even Donald Trump tweet generation. But what exactly are Markov chains, and why are they so unique?
Understanding Markov chains
Let’s say we are having a very nice day and are happy as a result, and that for some reason unknown to us, we only posses the emotional capacity to either be happy or sad. Can we predict what our feelings will be tomorrow? We know that our feelings tomorrow will be dependent on our feelings today; that is, a probabilistic function where the input is today’s mood and only today’s mood. Or in other words, a Markov chain!
 So how do we do this? Let a happy day and a sad day each be states. We will represent these as nodes on a graph. Now we need some probabilities for the changing of states. Suppose we consider ourselves optimistic people: let’s say there’s a 5/6 chance that if we are happy today, we will be happy tomorrow, and a 1/2 chance if we are sad today, we will be happy tomorrow. Since something must happen tomorrow (all apocalyptic events excluded), then the sums of the probabilities leaving each state must add to 1.
So how do we do this? Let a happy day and a sad day each be states. We will represent these as nodes on a graph. Now we need some probabilities for the changing of states. Suppose we consider ourselves optimistic people: let’s say there’s a 5/6 chance that if we are happy today, we will be happy tomorrow, and a 1/2 chance if we are sad today, we will be happy tomorrow. Since something must happen tomorrow (all apocalyptic events excluded), then the sums of the probabilities leaving each state must add to 1.

♪ Because I’m happy with a 5/6 chance tomorrow if I’m feeling happy today… ♪ Image: Frank Schwichtenberg, CC BY-SA 4.0
This is an example of a two-state Markov chain, and while simple, it presents a useful visual aid to help our understanding. Much more formal and rigorous definitions can be found online, but in a nutshell, a Markov chain consists of a set of states where the probability of transitioning to any state is solely dependent on the current state. This dependence is called the Markov property and is what makes this neat piece of maths unique.
We can even use this Markov chain to predict how many happy days we’re going to have over the next week. One way we can do this is by following the chain by hand. Take a fair six-sided die and put a finger on the happy state: let’s say today was a good day. Now roll the die and if 1–5 is rolled, follow the looped arrow back to the happy state, else follow the arrow to the sad state. If we were unfortunate enough to find ourselves on the sad state, let even rolls—2, 4 and 6—send us down the arrow to the happy state; and odd—1, 3 and 5—loop back round to the sad state. If we make seven rolls where each roll is a new day, our finger will conclude on the prediction for how we’ll be feeling a week today. If we note the state after each roll, we’ll have predictions for each of the seven days. Now we can plan our week accordingly!
What about in a month then? Or a year? Following this diagram for 365 days, the rolling becomes a bit tedious. Instead, we can speed this up by taking ideas from linear algebra, and creating a transition matrix. Let each column of the matrix represent the current state and the rows represent the probabilities of transitioning to each state. For this example, the transition matrix is given by 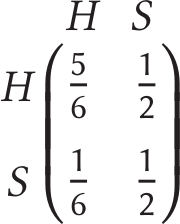 where $H$ = happy and $S$ = sad. We can use this representation to make a prediction for any number of days in the future. It should be noted that this could equally work with the columns and rows swapped, but as long as we’re conscious of which way we’re doing it, it simply becomes context. We can check whether the matrix has been created properly; the columns (in this case) should add to 1. If they don’t, something has gone horribly wrong! Say we wanted a prediction for two days’ time. We first raise this transition matrix to the power of 2, giving the following calculation:
where $H$ = happy and $S$ = sad. We can use this representation to make a prediction for any number of days in the future. It should be noted that this could equally work with the columns and rows swapped, but as long as we’re conscious of which way we’re doing it, it simply becomes context. We can check whether the matrix has been created properly; the columns (in this case) should add to 1. If they don’t, something has gone horribly wrong! Say we wanted a prediction for two days’ time. We first raise this transition matrix to the power of 2, giving the following calculation:
\[ \begin{pmatrix}{\frac56}&{\frac12}\\ {\frac16}&{\frac12} \end{pmatrix}^2 = \begin{pmatrix} {\frac{5}{6} \times \frac{5}{6} + \frac{1}{2} \times \frac{1}{6}}&{\frac{5}{6} \times \frac{1}{2} + \frac{1}{2} \times \frac{1}{2}}\\ {\frac{1}{6} \times \frac{5}{6} + \frac{1}{2} \times \frac{1}{6}}&{\frac{1}{6} \times \frac{1}{2} + \frac{1}{2} \times \frac{1}{2}} \end{pmatrix} = \begin{pmatrix} {\frac79}&{\frac23}\\ {\frac29}&{\frac13} \end{pmatrix}. \]
Let’s see what is going on here by looking at the first entry of the new matrix. Like before, this is the probability of starting on happy and finishing back on happy, but this time for the day after tomorrow. If we relate this back to the graph, we can see that each term is a different possible path of probabilities (try saying that five times as fast) for exactly two days; $(5/6) \times (5/6)$ is happy tomorrow then happy the day after, and $(1/6)\times (1/2)$ is sad tomorrow and back to happy the day after. We then just choose a starting state. Like before, let’s be happy today: we represent this as a vector $\left(\begin{smallmatrix} 1 \\[2pt] 0 \end{smallmatrix}\right)$. We then do the following calculation with our matrix we just raised to the power of 2:
\[ \begin{pmatrix}{\frac79}&{\frac23}\\{\frac29}&{\frac13} \end{pmatrix} \begin{pmatrix} 1 \\ 0 \end{pmatrix} = \begin{pmatrix} {\frac79}\\ {\frac29} \end{pmatrix}. \]
In return, we will get this column vector where the first entry is the probability of being on the happy state in exactly two days, and the second entry is being on the sad state. The cool thing is that we can put this matrix to any power $n$, which will give us a set of predictions for the $n$th day from today. Now, we’re mathematicians, so we need to do what any good mathematician should do and ask what happens when $n$ tends to infinity. This is something called the long run average probability and can be used to predict the behaviour of the Markov chain for some arbitrary but significant time in the future. This can be found analytically by taking some more ideas from linear algebra including a process called matrix diagonalisation, which would call for the use of more advanced mathematics. So instead, with a little rough-around-the-edges Python code (see the bottom of this article) we can get a pretty good idea. As $n$ gets very large, it is seen that the happy state tends to $0.75$, or $3/4$, and the sad state to $0.25$, or $1/4$. Therefore, given a significant amount of time in the future, this Markov chain is predicting a 75% chance we’ll be happy: not bad, all things considered.
We should, of course, acknowledge the limitations of this as a model. There are plenty of emotions not taken into consideration, nor whether a day holds special significance, eg a birthday. However, it’s easy to imagine how this can be expanded to accommodate for these other ideas with bigger graphs and larger matrices. The below graph shows how we might add a third emotion, for example boredom. Assign the probabilities based on whatever data we may be using, then fill out the graph accordingly.
 We must be careful, however! When adding the new probabilities, it’s vital we ensure the sum of all arrows exiting a state still sum to exactly $1$. In addition, we are after all working with probabilities, and as such should be aware that a low chance does not mean impossible, and a high chance does not mean inevitable. This is just a model, and real life is rarely so organised.
We must be careful, however! When adding the new probabilities, it’s vital we ensure the sum of all arrows exiting a state still sum to exactly $1$. In addition, we are after all working with probabilities, and as such should be aware that a low chance does not mean impossible, and a high chance does not mean inevitable. This is just a model, and real life is rarely so organised.
What can be done with them?
Markov chains are used in a wide array of industry-based mathematics. But, with the rise of the technological age, these more light-hearted, fun and fascinating applications have emerged. A very interesting such use of these can be text prediction; quite a simple idea but we can have a lot of fun with it! If we take a few short sentences, say
“I love Markov chains.”
“Markov chains love me.”
“Markov is I.”
and we wanted to generate new original sentences from these, how could we do it? Representing each word as a state, we can create a Markov chain. The probabilities between states are then intuitively derived from the frequency of words following each other within these sentences. Take the word ‘Markov’. In these short sentence, the word ‘Markov’ is followed by the word ‘chains’ or ‘is’. However, if we look at the frequencies of these words, we have that ‘chains’ follows ‘Markov’ $2/3$ of the time, and ‘is’ for $1/3$. Do this analysis for every word and we have all the states and probabilities we need. Hence, like before, we can draw this up.
Once again, the probabilities allow for this to be played with using a fair six-sided die, with which we can generate some new sentences:
“I love Markov is I love Markov chains love me.”
“Markov chains love Markov chains.”
“I.”
Notice that not every pair of states has a pair of probabilities between them. This is because some states have a zero chance of following the current word. For example, in none of the three short sentences does ‘me’ directly follow from ‘chains’, leading to the zero chance of ‘me’ following ‘chains’ in the Markov chain. We could include these arrows on our graph, annotating them with the zero chance, however this would lead to an unnecessary clutter, especially since these extra arrows would be inconsequential for our purposes anyway.

Fake Donald Trump tweets generated by a Markov chain built by Filip Hráček. Image: Reproduced with permission from Filip Hráček
There’s an amusing example of this method in Hannah Fry and Thomas Oléron Evans’s The Indisputable Existence of Santa Claus where they use this method to generate new Queen’s speeches with interesting results. Similarly, the sentences we’ve generated aren’t really sentences despite how much hilarity ensues, but imagine if we had a much larger data set\dots say someone’s Twitter. Twitter’s public availability lends itself as a large library of data containing peoples’ thoughts and opinions that we can use. One such person is 45th president of the United States, Donald Trump, who often likes to express his opinions publicly with questionable legitimacy, although here, this can work in our favour. Filip Hráček is a programmer from the Czech Republic who, as an experiment, created a Donald Trump tweet generator using Markov chains.
The probabilities become a lot more reliable when we introduce this large data set, causing the system to generate more coherent sentences. They’re still not perfect, but as was mentioned, this data coming from Donald Trump works in our favour. By setting each word in the tweet to a state, like before, the probabilities become more fine-tuned with the vast amount of data at hand. This model also employs something called an order-2 Markov chain. What this means is that instead of the next state being solely dependent on the previous, the model takes into account two states, or in the case the words, for making the decision on the next. A Reddit user under the handle Deimorz took this one step further and created a subreddit entirely populated with posts and comments generated by bot accounts using Markov chains. We can’t interact with them, but it’s unnerving to see the conversations they have relating to some topic unknown to us, especially since the bots are seemingly fully invested. There are quite a number of diverse experiments such as these online which use Markov chains, and which you can play with. Curiously, on the more serious side of application, this is the very primitive idea behind text prediction on mobile phones.
Andrey Andreyevich Markov, a Russian mathematician born in 1856, was the creator of this piece of mathematics in his work in probability theory. They have since been used in applied mathematics spanning many fields. Uses of Markov chains appear in computer science, business statistics, mathematical biology, contributing to Google’s PageRank, predictive text on mobile phones, and plenty more. What’s curious is that Markov developed this process for letter analysis in his native language of Russian: given a letter, calculating what is likely to be the next one. His motivation was based in probability and statistics and idea called the law of large numbers. For further reading, I’d recommend a research paper, The five greatest applications of Markov chains by Philipp von Hilgers and Amy N Lanville, which explains some of the most revolutionary uses of Markov chains in history, including going more in depth into Andrey Andreyevich Markov’s own application. It talks about historical uses in information theory, computer performance, and was one of the most interesting reads I found when conducting research for this article.
Now it’s your turn! Get out some dice and play with these examples, or even come up with your own. There is so much more to this neat piece of mathematics worth exploring, far too much to squeeze into this article. So I implore you to get reading, and start creating!
Python code for predicting mood
Some simple but functional code to find the probabilities for 52 weeks:
import numpy as np
A = np.array([[5 / 6, 1 / 2], [1 / 6, 1 / 2]])
B = []
for x in range(0, 365, 7):
b = np.linalg.matrix power(A, x)
start = np.array([[1], [0]])
c = np.dot(b,start)
B.append(x / 7)
B.append(c)
print(B)
More from Chalkdust

In conversation with Christina Pagel
Ellen Jolley asks for (independent) Sage advice
How can we tell that 2≠1?
Maynard manages to prove that 2≠1 in less space than it took Bertrand Russell to prove that 1+1=2
Colouring for mindfulness
Florian Bouyer explains the beautiful geometry behind his mathematical colouring-in designs.
The birth of the Fields medal
Who is behind the so-called Nobel prize of mathematics? Gerda Grase investigates.
(Not) squaring the circle
Sam Hartburn attempts the impossible
Will this article ever end?
Emilio McAllister Fognini explores the maths that made Turing so famous