
Have you ever browsed one of your friend’s playlists and discovered that you both share almost the same music? Maybe you have some additional songs and perhaps he has a band that you have never heard of before, but basically you have the same music. Is there a way to get a proper measure of how similar your music is? If you could compare your music with every person you know, is there a way of ranking playlists according to which is most similar to yours? It is possible that the playlist that is closest to yours contains songs that you have never heard before but that you will really enjoy.
To define the problem a bit more formally, let $\mathcal{A}$ be the set of songs that you have, $\mathcal{A}=\left\{ a_1, a_2, \dots, a_n \right\}$, where $a_i$ is each individual song, which means that you have $n$ songs; and let $\mathcal{B}$ be your friend’s playlist, with $\mathcal{B}=\left\{ b_1, b_2, \dots, b_m \right\}$. There is no need for you and your friend to have the exact same number of songs, so $n$ might be different to $m$.
From those two sets, $\mathcal{A}$ and $\mathcal{B}$, we want to define a measure that tells us how similar they are. If we focus first on the songs that you both have in common, we let $\mathcal{C} = \mathcal{A} \cap \mathcal{B} = \left\{ c_1, c_2, \dots, c_p \right\}$, which means that you share $p$ songs (where $p$ might be zero, in which case you have no music in common) and then the songs that you both have in total, $\mathcal{D} = \mathcal{A} \cup \mathcal{B} = \left\{ d_1, d_2, \dots, d_q \right\}$, where $q$ is the total number of distinct songs that you have. Let’s assume that between both of your playlists you have at least one song, so $q>0$. From this we define the similarity between your music preferences as
$$\operatorname{Sim}(\mathscr{A},\mathcal{B}) = \frac{\left|\mathcal{A} \cap \mathcal{B}\right|}{\left|\mathcal{A} \cup \mathcal{B}\right|} = \frac{|\mathcal{C}|}{|\mathcal{D}|} = \frac{p}{q}, $$
where $|\mathcal{A}|$ denotes the number of elements in $\mathcal{A}$, that is, the number of songs that you have.
This measure of the similarity between your music has very interesting properties. First, as the number of songs you both share is obviously not negative, then the measure is also not negative; and also, the number of songs that you share has to be less or equal than the total number of songs that you both have, so the similarity is smaller than one. Written in a more mathematical way, we say that
$$ 0 \leq p \leq q \hspace{20pt} \Rightarrow \hspace{20pt} 0 \leq \frac{p}{q} \leq 1 \hspace{20pt} \Rightarrow \hspace{20pt} \operatorname{Sim}(\mathcal{A}, \mathcal{B}) \in\left[0,1\right]. $$
A second property of this measure is that if you and your friend have exactly the same music, then $\mathcal{C} = \mathcal{D}$, which means that $p = q$, and so the similarity of your music is exactly one. In other words, $\operatorname{Sim}(\mathcal{A}, \mathcal{A}) = 1$.
A third property that we get from measuring in this way is that $\operatorname{Sim}(\mathcal{A}, \mathcal{B}) =\operatorname{Sim}(\mathcal{B}, \mathcal{A}),$ in which case we say that the measure is commutative.
A final property is the effect of acquiring a new song. If you add that new song to your collection but your friend does not, then the size of the intersection remains the same whilst the size of the union increases as a result of that brand new song and so the similarity would decrease. On the other hand, if you both buy the same song, then the size of the intersection $p$ increases by one, and so does the union. For that reason, unless the similarity was already one (which means that your music was identical) then the measure increases thanks to that new song.
With this measure you could compute the similarity between your music and every person that you know and then rank them from the one with the most similar music to the one whose taste is most different.
Social Networks

Similarity in Social Networks
The same idea on similarity could be applied to a social network like Facebook. In this case you may consider your set of contacts as the set to be compared, and the similarity is based on the amount of contacts that you have in common.
Since Facebook provides the number of contacts that you and one of your friends have in common, then a formula that we can use is
$$\operatorname{Sim}(\mathcal{A},\mathcal{B})=\frac{p}{n+m-p},$$
where $n$ and $m$ are, again, the number of contacts that each one of you have, and $p$ is the number that you have in common. If you rank each one of your contacts based on your similarity, then the ones occupying the first places are likely to be your lifelong friends and/or family.
The idea of similarity in a social network can be easily applied to create suggestions of other friends that you might share, places of interest or events.
If we try to define similarity on a social network like Twitter, then we have a difficult issue. On that social network you can have “followers” and people that you “follow” and the two are completely different. If we only focus on one of them, for example the followers that you have (which we can call the “Popularity” of a person) then you could have a high similarity with another account but never receive or read the same tweets. If we only focus on the accounts that you follow, then you could create an account and follow the same 164 Twitter accounts that Katy Perry follows (who happens to be the most popular person in Twitter) and conclude that your account is extremely similar to hers. However, it is very unlikely that you will end up with the 66.7 million followers that she has. For that reason we can define two different measures of similarity for this social network.

Social Networks
We can think of the first one as the “following similarity”, namely $\operatorname{Sim}_{\text{F}}(\mathcal{A}_{\text{F}}, \mathcal{B}_{\text{F}}) $, which is based on the accounts that you and your friend decided to follow, expressed as $\mathcal{A}_{\text{F}}$ and $\mathcal{B}_{\text{F}}$ respectively, and computed the same way as we did with your contacts on Faceboook or your songs in your playlists. This function measures how similar your news feeds are, or, in other words, how likely it is that when you both sign in you will both receive the same tweets.
On the other hand, we define the “popular similarity”, $\operatorname{Sim}_{\text{P}}(\mathcal{A}_{\text{P}}, \mathcal{B}_{\text{P}})$ which is based on the followers that you both have on Twitter, with the higher the similarity, the more likely it is that the same people will read tweets from both of your accounts.
Having two different measures of similarity is not very useful and we need a way to mix them. We have several options for combining these measurements, for example, a weighted combination of both, like
$\operatorname{Sim}_{+}(\mathcal{A}, \mathcal{B}) = w \hspace{2pt} \operatorname{Sim}_{\text{P}}(\mathcal{A}_{\text{P}}, \mathcal{B}_{\text{P}}) + (1-w) \operatorname{Sim}_{\text{F}}(\mathcal{A}_{\text{F}}, \mathcal{B}_{\text{F}}) ,$
for a given parameter $w \in [0,1]$. That number $w$ can be interpreted as the relevance that the popularity has over the accounts that are being followed. If, for example, we take $w=1/2$ then we are saying that they are both equally important, and if we take $w=0.9$ then we place more importance on the popular similarity. Having to decide the value for $w$ might be a bit arbitrary.
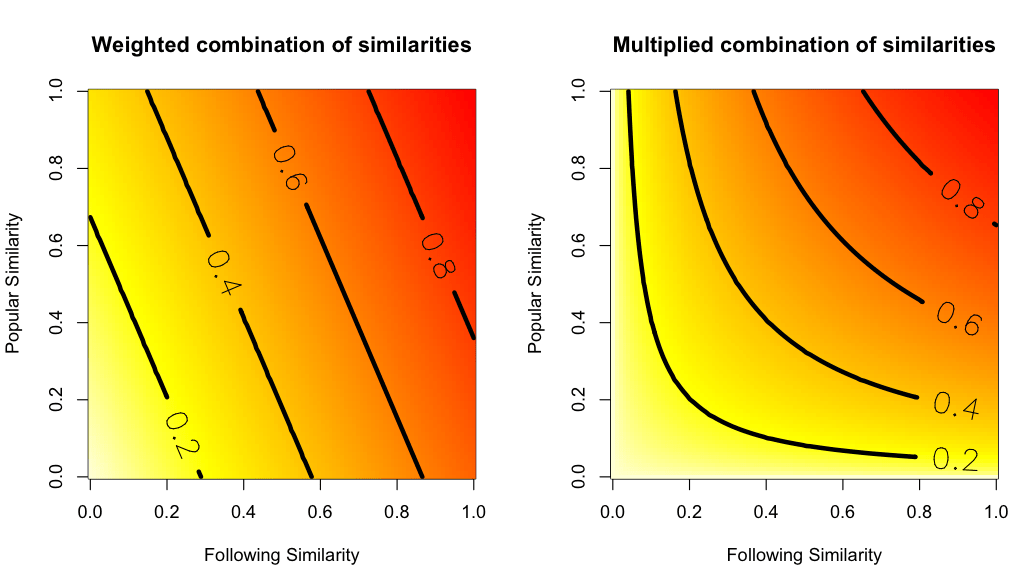
Left: a weighted combination of the following and popular similarity. Right: the product of both similarities.
A second option would be to define the similarity as
$$\operatorname{Sim}_{\times}(\mathcal{A},\mathcal{B})=\sqrt{\left[\operatorname{Sim}_{\text{P}}(\mathcal{A}_{\text{P}}, \mathcal{B}_{\text{P}})\right]\left[\operatorname{Sim}_{\text{F}}(\mathcal{A}_{\text{F}}, \mathcal{B}_{\text{F}})\right] },$$
which is simply the multiplication of both measurements. If you and your friend have a following similarity of 0.7 and a popular similarity also of 0.7, then the simple multiplication of the two numbers would be just under 0.5, so in order to avoid such small numbers, we incorporated the square root.
It is easy to see that these new measurements that combine popular similarity and following similarity are also between 0 and 1. So you can now compare your similarity to one of your friends both on Facebook and Twitter.
Therefore, we have obtained a way to compare sets that might have different sizes, like your playlists, your Facebook friends or your popularity on Twitter. This is very useful since obtaining a measure of your music similarity might help you find groups that you have never heard of before, and on social networks might result in you finding people that you had not been able to find before or posts and tweets that might interest you.
More from Chalkdust

Closing the first Black Mathematician Month
Reflecting on what we've learnt over the past few weeks.
In conversation with Vernon Morris
The co-author of a recent paper on diversity in professional STEM societies talks about access to science.
In conversation with Talitha Washington
Meet Talitha Washington, an activist, mathematician, and professor
In conversation with Jonathan Farley
We spoke with Jonathan Farley about his research and experiences as a black mathematician.
In conversation with Tanniemola Liverpool
As part of Black Mathematician Month, we spoke to the Bristol University professor about access schemes and the importance of mentors.
In conversation with Olubunmi Abidemi Fadipe-Joseph
Meet Olubunmi Abidemi Fadipe-Joseph, an active promoter for women in mathematics from Nigeria