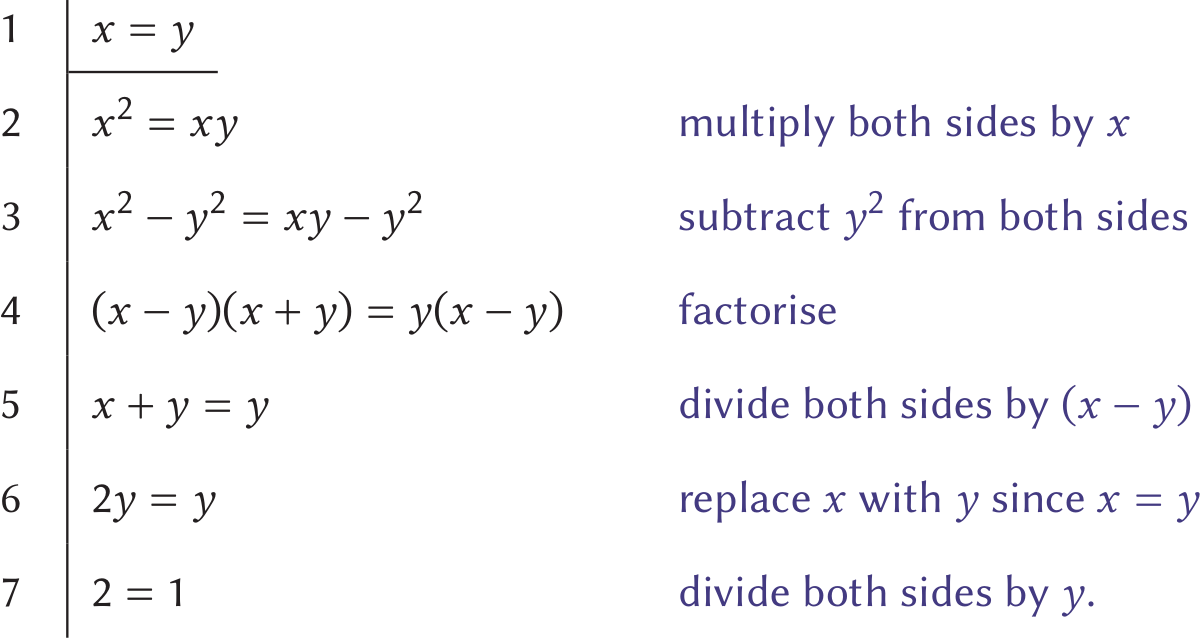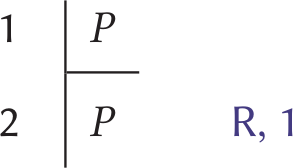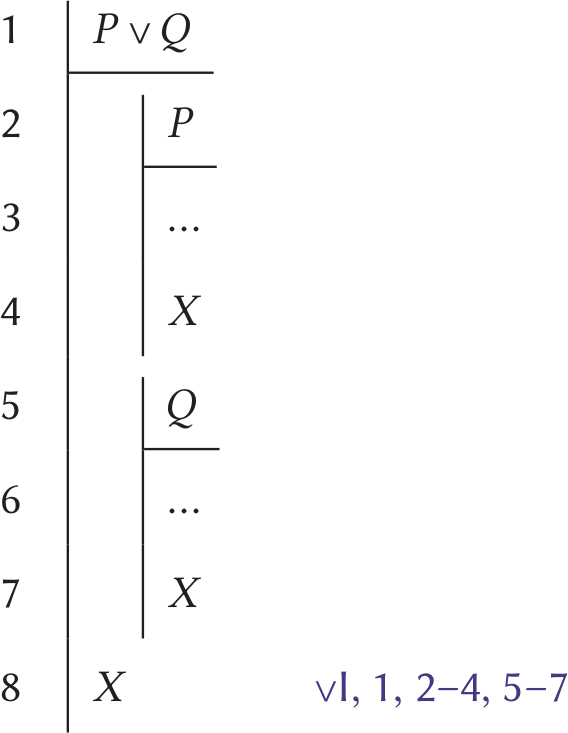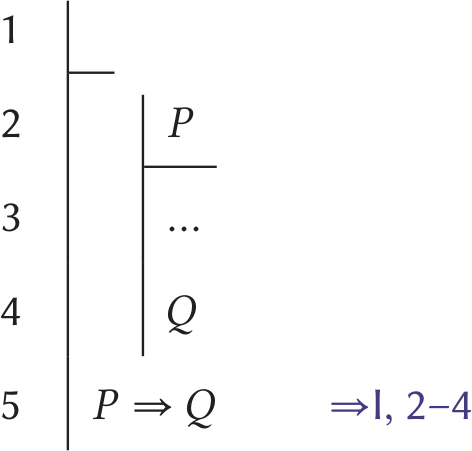This interview was conducted on 11 August 2020, and our discussion of the pandemic reflects this.
Given everything we read in the news during this pandemic, it is no longer a surprise to anyone that maths plays a crucial role in solving problems that affect our daily lives. This has been thrown into the spotlight recently, with mathematical modellers advising government policies across the world and statisticians holding the key to decoding the chaos of pandemic data; but it has been going on behind the scenes for quite some time. Operational research (OR) is the branch of applied maths dedicated to using maths to make better decisions, and it can be applied to almost any field. If that sounds vague, fret not, because we sat down with Christina Pagel, professor of operational research and director of the Clinical Operational Research Unit (CORU) at UCL, and a member of the Independent Sage (Scientific Advisory Group for Emergencies) committee, to clear up exactly what it entails.
“Operational research is a really applied branch of maths, and you can use any kind of maths, as long as you’re answering a real world problem.” But some maths is more typical of operational research than others. For example, queueing theory is the mathematical theory behind modelling queues and making them more efficient, ie deciding who gets served in what order. Another classic of OR is optimisation, which is choosing how to allocate resources given certain constraints and goals, such as minimising costs or maximising profit. “That’s used everywhere from transport, health care, emergencies… The travelling salesman is a really well-known optimisation problem—how do I visit these destinations in the shortest time possible?” Chalkdust would like to apologise to readers for any distress caused by the reminder of their decision maths A-level module.
Data analysis is crucial too. “How do we use the data that people have to help them make decisions? That’s a big branch of operational research.” And of course, as with most branches of maths these days, simulations play a big role. “Say in queueing theory, it’s fine as long as you have Poisson arrivals and exponential service times, but once you get to real life and see that actually you have this funky algorithm for choosing who gets served and how long it takes, then you start having to use simulation because you just can’t solve it analytically.”
But the field is very problem-focused, and for Christina the maths is of only secondary interest to the questions themselves. “I’ve become less interested, as I become older and more senior, in the novelty or difficulty of the mathematics and much more interested in the problem.” And it shows—she has worked on more problems than there are maths puns in an issue of Chalkdust.
Paediatrics, politics, periods…

Great Ormond Street hospital, c~1872. Image: Welcome Collection CC BY 4.0
As director of CORU at UCL, Christina focuses on operational research applied to healthcare. She recently held a position as researcher in residence at Great Ormond Street hospital (GOSH), a children’s hospital in London, helping them solve problems like predicting how many beds they will need, or when the children’s respiratory disease peak will be. The peak is about a month and half earlier than the adult flu peak, and Christina built a model for GOSH to let them know when it begins. This is crucial to know because when it comes, “demand will double very quickly and they don’t have more capacity.”
This is only the tip of the iceberg in regards to all the problems healthcare needs mathematicians to solve. Another classic operational research problem that CORU has worked on recently is investigating the ideal placement of the UK’s 11 specialised ambulance services which transport sick children from local hospitals to paediatric intensive care hospitals, as well as the possibility of changing the number of ambulances at each location. “We also do simple models of vaccination programs for the [UK government’s] Department of Health and Social Care. If I’m introducing a new vaccine, what is the impact of other vaccines? How many times do I have to vaccinate? That involves a mixture of theoretical modelling and then data analysis. Sometimes we mix them together, like in queue models for how many health visitors you need to serve a certain community with certain needs, which is something we’re doing right now for instance.”
If you can’t articulate what you’re trying to do, then all of your solutions for getting there are meaningless.
For even further evidence of the infinite set of problems mathematicians are in demand to solve (as if we needed it), Christina tells me she began a fellowship in the US in 2016 to study their healthcare system, but unexpectedly found herself more useful in political science. “Within about two months of me getting there, Trump was elected. And it became really clear that he was going to try to repeal Obamacare. He failed, but I didn’t know that at the time.” She felt there was no point working to improve a health system that was about to be upheaved, but she saw politicians arguing about Obamacare and she realised that she had a unique perspective on how to understand their feuds.
“I thought, ‘Do we understand what the goal is in the situation?’ That’s a classic operational research point of view. If you can’t articulate what you’re trying to do, then all of your solutions for getting there are meaningless.” She devised a survey for politicians to understand what their goal was. The survey had thirteen possible goals that were developed with a focus group of serving politicians and academic health policy experts, such as ‘improve health’, ‘reduce costs’ and ‘reduce inequality’, and participants were asked to rank them on importance. Using a voting system, she was able to give the items an ‘overall’ ranking, and used a stats technique for plotting multidimensional priorities to see how people on different parts of the political spectrum felt about healthcare. “It wasn’t anything particularly sophisticated, but they just hadn’t ever done that!” What was common sense to Christina was a completely new way of looking at the problem to political scientists.

For Christina, applied maths goes far beyond merely applying maths. She’s an interdisciplinary science communicator able to turn her hand to everything from politics to physics to biology. Image: Reproduced with permission from Christina Pagel
The methodology was a triumph in and of itself—perhaps fortunately, since the more challenging task of showing that politicians agreed on the goals didn’t transpire quite as planned. “I thought everyone would say improving health is the most important thing. But actually, improving health was only most important for Democrats, and second most important was reducing inequalities and improving access to healthcare. Whereas, for Republicans, the most important thing was reducing costs, and the second most important thing was reducing the involvement of government in healthcare, which to me was really bizarre, but that was important for them. Improving health came fifth out of thirteen, and last was reducing inequality.” But even though they could not agree, the survey still clarified exactly why they couldn’t agree. “It’s really helped them understand how they can talk to each other. For instance, if you’re a Democrat, and you want to push a policy because it reduces inequality, to your Republican colleagues that’s not the angle you use, you have to explain how it reduces costs.”
She is now working on a project looking at women’s period pain. “It’s not really my expertise, but if no one else is going to do it, then I’ll do it.” She is working with the Health Foundation to look at GP records to quantify the problem, which she hopes will convince medical researchers to give the issue serious attention. “80% of women at some point in their lives suffer from really bad period pain, and about 20% have some years of their life where actually it’s debilitating for two or three days a month. People have just found a way to live with it, when you shouldn’t have to live with that—why should you have to live with that? So we’re now trying to take it further and make it into a bigger project.” Picking up a problem wherever she sees one to solve is rather a habit of hers it seems. Of course, healthcare has had one particularly big problem to solve recently.
…and pandemics
Well, we had to talk about it eventually.
Operational research has played a crucial role in managing the pandemic from the beginning, and Christina laments that even better use of it has not been made. “There are loads of places operational research could have helped [the UK government] to do better.” An obvious issue is distribution of PPE (personal protective equipment), but there are many examples. “For instance, 30% of people with Covid-19 in intensive care units (ICUs) had kidney failure, so the whole country ran short of renal medicine, and that had knock on effects on people receiving dialysis.” When medicine is in short supply like that, how should it be distributed and prioritised? “How do you decide how many ICU beds you need when you’re reorganising hospitals? How do you decide how many emergency hospitals you need, like the Nightingales? All of that is OR. Even things like oxygen supply—Covid leaves so many people on supplemental oxygen that hospitals were running short, so how do you manage that? Because if you run out, then everyone in the hospital who needs oxygen is screwed which you obviously don’t want.”
Christina has been playing her part as a member of Independent Sage—or, as she affectionately calls it, “indie Sage”—a group of scientists who produce independent advice on the UK’s handling of the pandemic, to challenge and analyse that given by the government’s official scientific advisory group, Sage. Although initially she was expecting to be doing operational research, it became more a public communication of science role. It turns out this is something she excels at. “Because I’ve been working across disciplines—clinicians, patients, people in the government, local commissioners—I’ve had to always try to explain things to lots of different types of people. That’s been really helpful in indie Sage, in that I’m not in a silo.” She now does weekly YouTube briefings (on the indie_SAGE channel) breaking down where we are at with the pandemic and collating government data from countries around the world, and reasonably regularly appears on TV and radio explaining the latest numbers.
I’ve been working across disciplines—clinicians, patients, people in the government, local commissioners—I’ve had to always try to explain things to lots of different types of people.
Independent Sage believes the UK government should be aiming to achieve elimination of Covid. “There’s a technical difference between elimination and eradication. Eradication is what we’re trying to do to polio and what we did to smallpox, but elimination is what New Zealand did, which is zero community transmission.” This would mean the virus can only enter the country via travellers, which Christina says could hopefully be handled with effective test and trace, and quarantine. “And once you’ve done that, you can go back to normal life! Masks, social distancing, you don’t have to worry about that stuff.” Critics of the strategy say it is simply unachievable. “But it’s not saying you’re never going to get a case. Small outbreaks are much easier to stamp down. It’s like in my house, I have a zero fire policy, I’m not going to let any fire come out, and if it does I’ll put a tea towel over it. We’re stuck in this limbo where you can open mostly but not completely, and if you relax when you haven’t got it down far enough it goes out of control. We’re saying get it down far enough, and you do that through really, really good contact tracing. You have to break the chain of transmission, that’s what South Korea did, that’s what China did.” Unfortunately, between speaking with Christina and writing this article, it’s starting to seem like this prediction may be coming true.
Elimination… is zero community transmission… and once you’ve done that, you can go back to normal life! Masks, social distancing, you don’t have to worry about that stuff.
So what does she think the UK should have done to get to such low levels of Covid? “You close down the areas that are really risky. We know outside is safe, but indoor pubs… it’s not a good idea. When countries opened shops, nothing really happened, but when they opened pubs, a few weeks later cases went up. Pubs, restaurants, bars, household parties… all of that causes superspreading events.”
If we had put on more restrictions in the short term while cases were still low, Christina believes we could, in a matter of weeks, have been able to achieve low enough levels to try to eliminate Covid and then we would be in a much better position to reopen schools and have students return to university. The returning of students to university poses a particular concern. “Younger people are much less likely to get symptoms, so they may get Covid and have no idea. And if we don’t have a really good contact tracing system, you can’t stop that. Whereas a really good contact tracing system stops people without symptoms going out, that’s how it works.” To clarify, she doesn’t believe the problem was opening up too early, but rather too quickly. “We opened up schools, and then two weeks later we opened shops, and two weeks later bars, and then gyms and then workplaces. But actually every time you open something, you need to give it about four weeks before you see anything in the data.” More patience with easing restrictions could have avoided the need for local lockdowns. “Local lockdowns are very damaging, whereas if they just waited and got to very low levels of Covid, it would have been fine.”
Master of all trades
Hearing how multi-disciplinary her current job is, perhaps it should not be a surprise that Christina has dipped her toes in quite a few fields before settling on maths, and has four master’s degrees to show for it. “I did maths as an undergrad, because I wanted to be a physicist, which made perfect sense at the time. And I thought quantum mechanics was awesome, so my first master’s was in quantum theory.” But when it came to choosing a PhD, she was told she would have to do a topic that was very heavy on tensors, and she understandably ran for the hills. “I thought, ‘I’m out then, it’s not for me!’ So I got a job and decided to do a part-time MA in classics because I always loved history, I loved ancient history, I loved Latin. I chose maths for my degree because you can’t skip from doing maths A-level to doing a master’s in maths, but you can do that in humanities.” Even though supposedly she needed an arts degree, she was admitted to the MA in classics with a first in maths, simply because people find maths impressive. “People will just give you the benefit of the doubt, it’s actually really handy.” She really enjoyed the opportunity to learn purely for pleasure.
I did a PhD in space physics, because I thought… ‘I want to be an astronaut.’
Eventually, physics called her back. “I did a PhD in space physics, because I thought… ‘I want to be an astronaut.’” Again, they were more than happy to accept a student with a background in maths. But she found herself frustrated with the obscurity of her work. “No one would have cared if I got it wrong. Literally, there were ten people in the world interested in that area of physics.” This is what inspired her to go into research that had a very direct application. “I thought this practical use of maths to help concrete problems is really appealing, so then I came to CORU.”
Although she had found her new calling, she couldn’t bring herself to give up her other passions yet. “I did another part-time master’s in medieval history, and again I really loved it.” The final master’s, which she did later in her career, was in statistics. “That was because people in health think if you do maths, then you’re a statistician. So I thought I’ll just do a stats qualification so I can say I am! But it wasn’t nearly as fun.” However, she did enjoy having her talents in maths reaffirmed. “I spend most of my time now doing project management, so it was kind of nice to do maths again and realise I could still do it.”
It is certainly good to hear that mathematicians have this power to jump around to any field they want. “The earlier you switch, the easier it is. For me, I looked at people who were working at CORU at the time, and about half the unit had done undergrads in physics, so I knew it was fine. We advertise that we don’t mind if people come with a different background. Maths teaches you how to think, and it is really flexible. You can’t change field and expect everything to stay the same. You have to be willing to learn a new programming language, a completely different way of looking at things. Operational research suits people who aren’t wedded to methods, or a certain type of way of doing things, but are actually really interested in real problems.” It may be a relief to anyone choosing modules or PhD topics that their choice won’t limit their career options—and in fact, as our conversation comes to a close, she has some advice for people making these decisions now. “If you’re thinking about doing a PhD, it does matter who your supervisor is. It’s quite an intense relationship, they’re the person who is going to be guiding you into becoming an independent scientist, and having someone who doesn’t want to do it or who is not that engaged can just be a really bad experience. And you have to find it interesting—because you’re going to be doing it for three years, and that’s a long time!”